这篇文章演示如何用 Anthropic 兼容 API,在终端里实现一个可读写文件、执行命令的简易版 Claude Code 助手。
Anthropic API 简介
目前业界使用最广泛的 LLM API 协议仍是 OpenAI 推广开的 Chat Completions API。但各大厂并未统一标准,其中 Anthropic 采用的是自家的 Anthropic API。
下面简单对比一下这两者的主要区别:
OpenAI Chat Completions API
- 端点:
/v1/chat/completions - 认证头部:
Authorization: Bearer ${api_key} - 请求格式:
{
"model": "gpt-4o",
"max_completion_tokens": 1024,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
]
}注:在最新 OpenAI Chat Completions API 文档中,max_tokens 已弃用,建议改用 max_completion_tokens。
Anthropic API
- 端点:
/v1/messages - 认证头部:
X-Api-Key: ${api_key} - 请求格式:
{
"model": "claude-sonnet-4-5-20250929",
"max_tokens": 1024,
"system": "You are a helpful assistant.",
"messages": [
{
"role": "user",
"content": [{"type": "text", "text": "Hello, how are you?"}]
}
]
}与 OpenAI Chat Completions API 不同,Anthropic API 的 system prompt 通过独立的顶层 system 参数传入。
关于 Anthropic API 协议的详细介绍,可以参考官方文档:Anthropic Messages API 官方文档。
如何调用 Anthropic API
目前国内各个大厂都已支持 Anthropic API。以 DeepSeek 模型为例,说明如何调用 Anthropic API。
调用 Anthropic API,可以直接使用 HTTP 客户端发送请求,也可以使用 Anthropic 提供的 SDK 发送请求。以 Python 为例,可以使用 anthropic.Anthropic() client 发送请求。
anthropic.Anthropic() 默认使用的 base_url 为 https://api.anthropic.com,为调用深度求索的 Anthropic API,可以先设置环境变量:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=${API_KEY}其中,API_KEY 填入深度求索开放平台的 API key,anthropic.Anthropic() 会读取这两个环境变量,完成 Anthropic client 的初始化。
接下来,发送请求:
import anthropic
def main():
client = anthropic.Anthropic()
message = client.messages.create(
model="deepseek-chat",
max_tokens=1024,
messages=[
{"role": "user", "content": "你好,请用一句话介绍你自己。"}
]
)
print(message.content[0].text)
if __name__ == "__main__":
main()输出:
你好,我是DeepSeek,由深度求索公司创造的AI助手,致力于用热情和智慧为你提供帮助!😊
完整的 DeepSeek Anthropic API 文档,可参考 DeepSeek Anthropic API 文档。
实现一个 Claude Code
参考开源仓库 nanocode,我们使用 Anthropic API 实现一个简易版的 Claude Code。
Claude Code 的实现过程如下:
用户输入 → LLM 思考 → 工具调用 → 执行结果 → LLM 继续思考 → ... → 最终回复由于 Claude Code 需要分析与编辑代码,以及执行 bash 命令,需要定义几个工具函数:
read:读取文件内容write:写入文件edit:替换字符串glob:查找文件grep:搜索内容bash:执行命令
例如,write 函数:
def write(args):
with open(args["path"], "w") as f:
f.write(args["content"])
return "完成"定义了工具函数后,转换成 Anthropic API 要求的 JSON Schema 格式,告诉 LLM 有哪些工具可用、参数是什么。
{
"name": "read",
"description": "读取文件并显示行号",
"input_schema": {
"type": "object",
"properties": {"path": {"type": "string"}, ...},
"required": ["path"]
}
}接下来是 Agent 循环,通过 messages 列表保存完整对话历史,以实现连续调用多个工具完成复杂任务:
while True: # 外层:用户交互循环
user_input = input("❯ ")
messages.append({"role": "user", "content": user_input})
while True: # 内层:代理循环
response = call_api(messages, system_prompt) # 1. 调用 LLM
for block in response["content"]:
if block["type"] == "text":
print(block["text"]) # 2. 打印 AI 回复
if block["type"] == "tool_use":
result = run_tool(...) # 3. 执行工具
tool_results.append(result) # 4. 收集结果
if not tool_results:
break # 5. 没有工具调用时退出循环
messages.append({"role": "user", "content": tool_results}) # 6. 返回结果给 LLM完整代码(200+ 行)
#!/usr/bin/env python3
"""simplecc - 简洁的 claude code 代码助手替代品"""
import glob as globlib, json, os, re, subprocess
import anthropic
# 使用环境变量进行配置
API_BASE_URL = os.environ.get("ANTHROPIC_BASE_URL", "https://api.deepseek.com/anthropic")
MODEL = os.environ.get("MODEL", "deepseek-chat")
# 初始化Anthropic客户端(从环境变量读取ANTHROPIC_API_KEY)
client = anthropic.Anthropic(base_url=API_BASE_URL)
# ANSI颜色代码
RESET, BOLD, DIM = "\033[0m", "\033[1m", "\033[2m"
BLUE, CYAN, GREEN, YELLOW, RED = (
"\033[34m",
"\033[36m",
"\033[32m",
"\033[33m",
"\033[31m",
)
# --- 工具实现 ---
def read(args):
lines = open(args["path"]).readlines()
offset = args.get("offset", 0)
limit = args.get("limit", len(lines))
selected = lines[offset : offset + limit]
return "".join(f"{offset + idx + 1:4}| {line}" for idx, line in enumerate(selected))
def write(args):
with open(args["path"], "w") as f:
f.write(args["content"])
return "完成"
def edit(args):
text = open(args["path"]).read()
old, new = args["old"], args["new"]
if old not in text:
return "错误: 未找到旧字符串"
count = text.count(old)
if not args.get("all") and count > 1:
return f"错误: 旧字符串出现 {count} 次,必须是唯一的(使用 all=true)"
replacement = (
text.replace(old, new) if args.get("all") else text.replace(old, new, 1)
)
with open(args["path"], "w") as f:
f.write(replacement)
return "完成"
def glob(args):
pattern = (args.get("path", ".") + "/" + args["pat"]).replace("//", "/")
files = globlib.glob(pattern, recursive=True)
files = sorted(
files,
key=lambda f: os.path.getmtime(f) if os.path.isfile(f) else 0,
reverse=True,
)
return "\n".join(files) or "无文件"
def grep(args):
pattern = re.compile(args["pat"])
hits = []
for filepath in globlib.glob(args.get("path", ".") + "/**", recursive=True):
try:
for line_num, line in enumerate(open(filepath), 1):
if pattern.search(line):
hits.append(f"{filepath}:{line_num}:{line.rstrip()}")
except Exception:
pass
return "\n".join(hits[:50]) or "无结果"
def bash(args):
proc = subprocess.Popen(
args["cmd"], shell=True,
stdout=subprocess.PIPE, stderr=subprocess.STDOUT,
text=True
)
output_lines = []
try:
while True:
line = proc.stdout.readline()
if not line and proc.poll() is not None:
break
if line:
print(f" {DIM}│ {line.rstrip()}{RESET}", flush=True)
output_lines.append(line)
proc.wait(timeout=30)
except subprocess.TimeoutExpired:
proc.kill()
output_lines.append("\n(30秒后超时)")
return "".join(output_lines).strip() or "(空)"
# --- 工具定义:(描述, 模式, 函数) ---
TOOLS = {
"read": (
"读取文件并显示行号(文件路径,非目录)",
{"path": "string", "offset": "number?", "limit": "number?"},
read,
),
"write": (
"写入内容到文件",
{"path": "string", "content": "string"},
write,
),
"edit": (
"替换文件中的旧字符串为新字符串(除非all=true,否则旧字符串必须是唯一的)",
{"path": "string", "old": "string", "new": "string", "all": "boolean?"},
edit,
),
"glob": (
"按模式查找文件,按修改时间排序",
{"pat": "string", "path": "string?"},
glob,
),
"grep": (
"在文件中搜索正则表达式模式",
{"pat": "string", "path": "string?"},
grep,
),
"bash": (
"运行shell命令",
{"cmd": "string"},
bash,
),
}
def run_tool(name, args):
try:
return TOOLS[name][2](args)
except Exception as err:
return f"错误: {err}"
def make_schema():
result = []
for name, (description, params, _fn) in TOOLS.items():
properties = {}
required = []
for param_name, param_type in params.items():
is_optional = param_type.endswith("?")
base_type = param_type.rstrip("?")
properties[param_name] = {
"type": "integer" if base_type == "number" else base_type
}
if not is_optional:
required.append(param_name)
result.append(
{
"name": name,
"description": description,
"input_schema": {
"type": "object",
"properties": properties,
"required": required,
},
}
)
return result
def call_api(messages, system_prompt):
response = client.messages.create(
model=MODEL,
max_tokens=8192,
system=system_prompt,
messages=messages,
tools=make_schema(),
)
# 将响应转换为字典格式以保持兼容性
return {
"content": [
{"type": block.type, "text": block.text} if block.type == "text"
else {"type": block.type, "id": block.id, "name": block.name, "input": block.input}
for block in response.content
],
"stop_reason": response.stop_reason,
}
def separator():
return f"{DIM}{'─' * min(os.get_terminal_size().columns, 80)}{RESET}"
def render_markdown(text):
return re.sub(r"\*\*(.+?)\*\*", f"{BOLD}\\1{RESET}", text)
def main():
print(f"{BOLD}simplecc{RESET} | {DIM}{MODEL} ({API_BASE_URL}) | {os.getcwd()}{RESET}\n")
messages = []
system_prompt = f"简洁的编码助手。当前工作目录: {os.getcwd()}"
while True:
try:
print(separator())
user_input = input(f"{BOLD}{BLUE}❯{RESET} ").strip()
print(separator())
if not user_input:
continue
if user_input in ("/q", "exit"):
break
if user_input == "/c":
messages = []
print(f"{GREEN}⏺ 已清空对话{RESET}")
continue
messages.append({"role": "user", "content": user_input})
# 代理循环:持续调用API直到没有更多工具调用
while True:
response = call_api(messages, system_prompt)
content_blocks = response.get("content", [])
tool_results = []
for block in content_blocks:
if block["type"] == "text":
print(f"\n{CYAN}⏺{RESET} {render_markdown(block['text'])}")
if block["type"] == "tool_use":
tool_name = block["name"]
tool_args = block["input"]
arg_preview = str(list(tool_args.values())[0])[:50]
print(
f"\n{GREEN}⏺ {tool_name.capitalize()}{RESET}({DIM}{arg_preview}{RESET})"
)
result = run_tool(tool_name, tool_args)
result_lines = result.split("\n")
preview = result_lines[0][:60]
if len(result_lines) > 1:
preview += f" ... +{len(result_lines) - 1} 行"
elif len(result_lines[0]) > 60:
preview += "..."
print(f" {DIM}⎿ {preview}{RESET}")
tool_results.append(
{
"type": "tool_result",
"tool_use_id": block["id"],
"content": result,
}
)
messages.append({"role": "assistant", "content": content_blocks})
if not tool_results:
break
messages.append({"role": "user", "content": tool_results})
print()
except (KeyboardInterrupt, EOFError):
break
except Exception as err:
print(f"{RED}⏺ 错误: {err}{RESET}")
if __name__ == "__main__":
main()运行方式
运行代码前,需要设置环境变量:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=${API_KEY}运行结果:
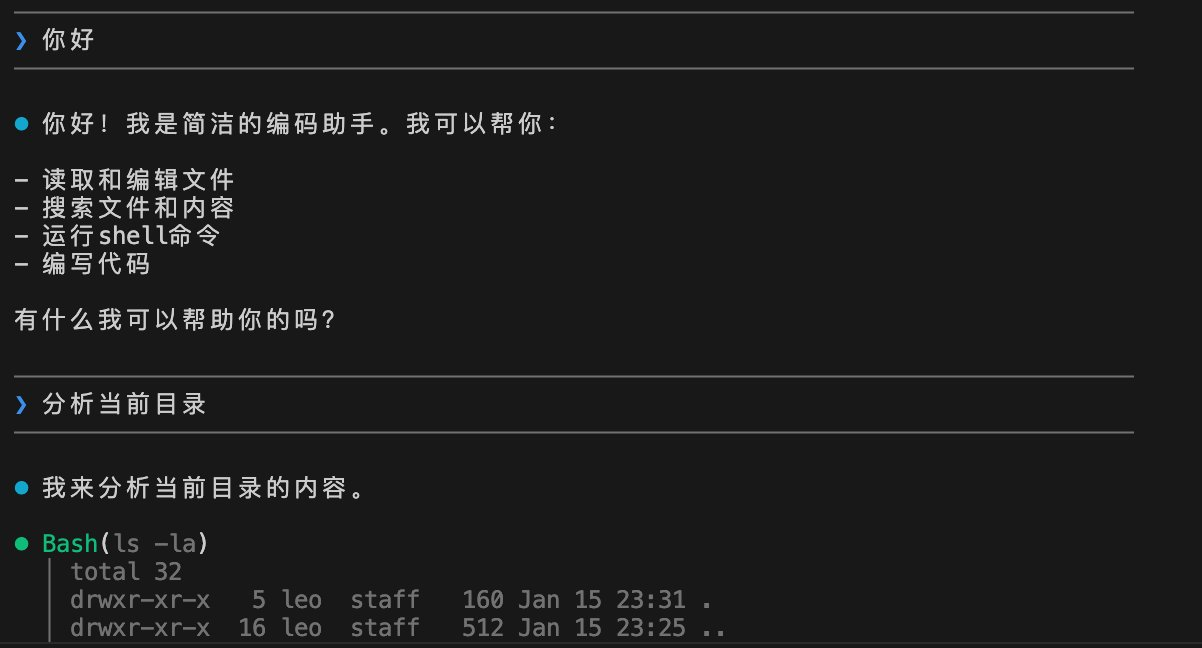
总结
这样,我们利用 DeepSeek 模型,实现了一个简易版本的 Claude Code 代码助手。有了 simplecc 的基本框架,接下来就可以不断往上面添加新功能。