记一次 socket 通信性能优化过程
上段时间测试人员对某个服务端程序进行了性能压力测试,发现当使用 JMeter 向程序并发发送 100 个请求后,再发送请求,则会出现程序无法响应的现象。想着这个问题比较棘手,就拖了不少时间。最近其他事情少了点,可以专心下来优化这个程序的性能,就着手开干了。
利用 Wireshark 和 Python 构造请求报文
客户端对向发送的请求报文进行了加密,且密钥存在过期时间。为方便构造请求报文,我们使用了 Wireshark 对请求报文进行抓包,然后直接将抓取的报文由 Python 程序发送。
我们先在 Wireshark 对过滤条件进行配置,服务端程序的监听端口为 5111,故配置tcp.dstport==5111 的过滤条件。
然后使用客户端向服务端程序发送请求,可以看到 Wireshark 显示出相应的请求报文: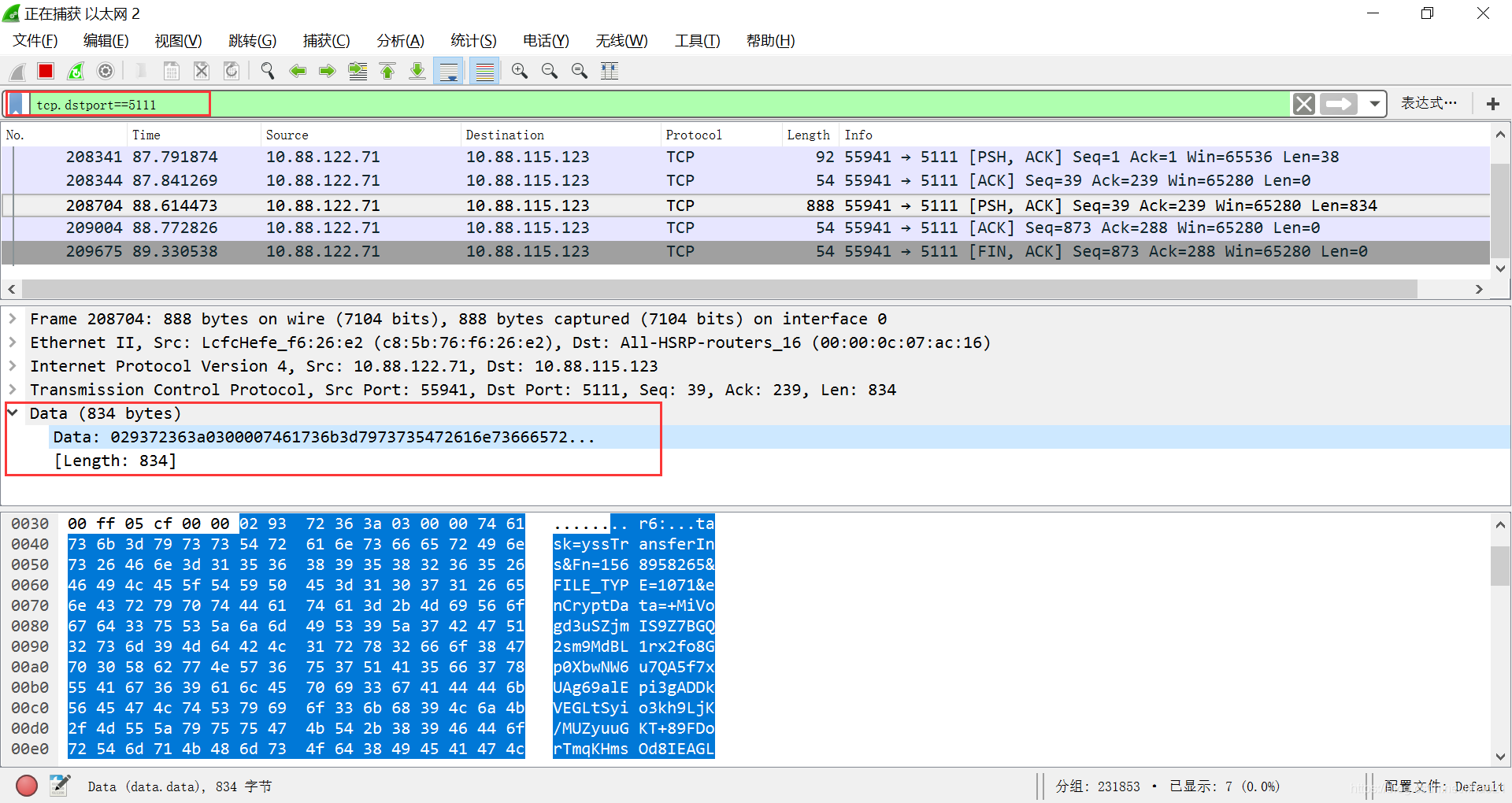
右键报文,选择显示分组字节,显示为C数组:
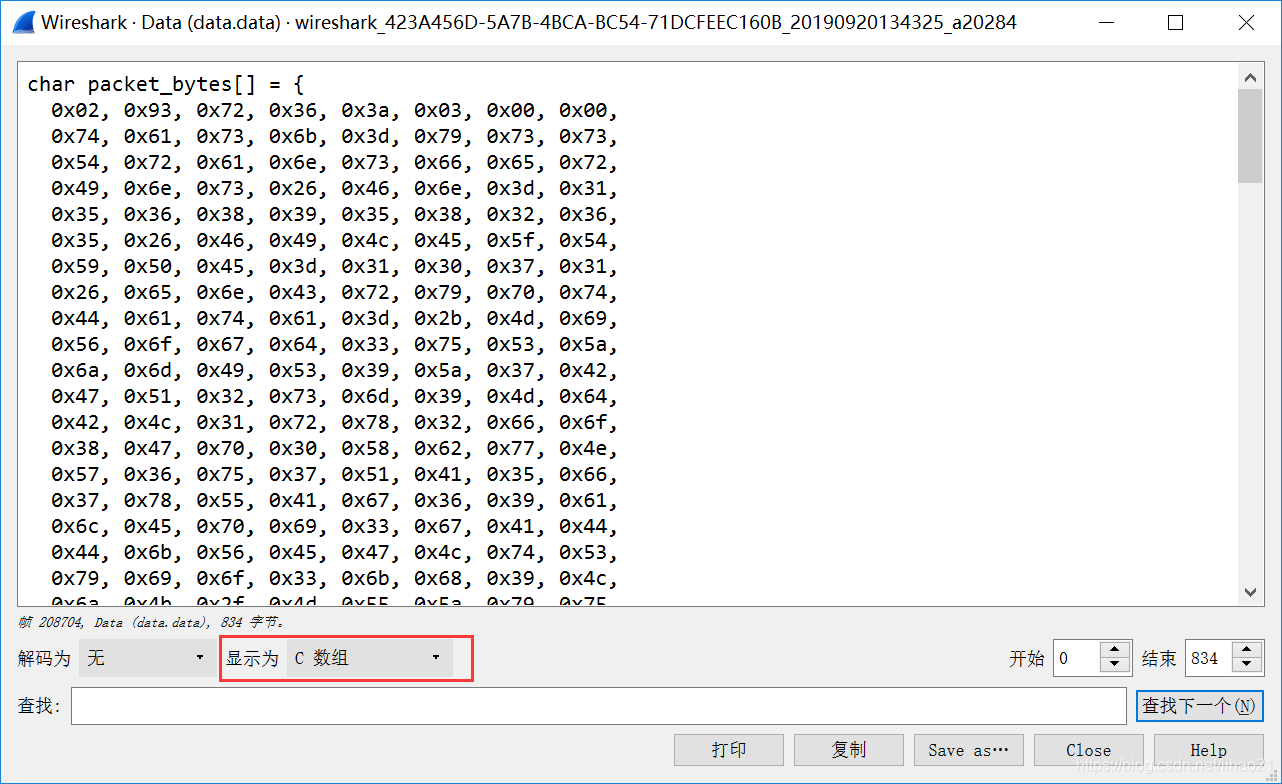
由于 JMeter 使用不多,并不太熟悉 JMeter 的使用,故这里使用 Python 来模拟客户端向服务端程序发送请求。
将相应的报文数据拷贝到 Python 程序,即可模拟客户端向服务端程序发送请求。为节省篇幅,Python 代码只截取了部分 msg 请求数据。
1 | #!/usr/bin/env python |
修复 FD_SETSIZE 的问题
Python 程序模拟同时有大量的客户端请求与服务端程序建立连接并发送请求。运行 Python 程序后,发现服务端对于前面的请求还是可以正常响应的,但运行一段时间后,服务端程序就无法响应了。使用top -c 命令查看服务器 CPU ,可以看到服务端程序基本占满 100% 的 CPU。使用 tail -f 命令查看程序日志,可以看到主线程不再打印日志,说明已卡住了。
为进一步确认主线程阻塞的地方,使用 pstack 命令来查看程序运行堆栈:
1 | Thread 1 (Thread 0x7f73bfbee720 (LWP 14182)): |
可以看到,程序阻塞在函数 ReadNetworkData 的 select 系统调用上了。
而服务端程序正常情况下运行堆栈如下,程序阻塞在epoll_wait 等待测试的文件描述符是否就绪。
1 | Thread 1 (Thread 0x7feaf652c720 (LWP 7815)): |
再观察服务端日志,可以看到当文件描述符的值小于 1024 时,是可以正常响应客户端请求的,但当文件描述符大于等于 1024 时,则会导致主线程阻塞在 select 调用上。
网上搜索关键词 select 1024 ,果然看到由于 FD_SETSIZE 参数上限为 1024 导致的惨案,例如,云风的 BLOG:一起 select 引起的崩溃。
原程序读取客户端请求数据的代码如下:
1 | while(1) |
select 中 FD_SETSIZE 参数上限为 1024,当需要测试的文件描述符大于等于 1024 时,则会出现越界的现象。由于程序中通过轮询来测试文件描述是否就绪,而测试的文件描述符又大于 1024,则会出现一直轮询下去的问题,导致程序一直阻塞在 select 调用上。
参考 stackoverflow 的例子,使用 poll 代替 select ,对程序进行改写,改写后程序代码如下:
1 | while (1) { |
使用 poll 改写 select 后,即使客户端连接数大于 1024,也没出现程序卡死的问题。
修复 accept 接受用户连接的问题
修复 FS_SETSIZE 的问题后,再提交给测试人员进行压力测试,发现仍然存在问题。向服务端程序并发发送 100 个请求后,再发送请求,仍然会出现无法响应的现象。
查看程序日志,发现当使用 Python 向服务端程序发送请求时,日志会出现上一个连接的 IP 和端口,也就是说,程序将上一个连接当成是新建立的连接来使用了。
这时,如果再从旧的连接读取或写入数据,会出现 “Connection reset by peer” 或者 “Broken pipe”的错误,这是由于旧的连接可能已经断开了。
于是怀疑 accept 调用是否存在问题。考虑到调用 accept 前使用 epoll_wait 来测试监听套接字是否就绪,且使用了 ET 模式,故监听套接字就绪时,可能已经有一个或者多个客户端连接进来,故只调用一次 accept 就可能会出现连接错误的问题。
程序原来的 accept 处理逻辑如下:
1 | if (fd==g_TcpSock) |
参考文章 《I/O多路复用之 epoll 系统调用》 的说明,改写了 accept 调用的逻辑:
1 | if (fd==g_TcpSock) |
改写后,不再出现连接错乱的现象,原来压力测试发现的问题也不再出现。
小结
这次对服务端程序 socket 通信性能进行优化,挑战还是不小,几次没有头绪差点想要放弃。通过分散自己的思维,翻看自己以前写的文章,最后还是顺利修复了问题。看来平时的积累非常重要,要加强平时的学习。
参考资料
- https://blog.csdn.net/lihao21/article/details/66475051
- https://blog.csdn.net/lihao21/article/details/67631516
- https://blog.csdn.net/lihao21/article/details/64951446
- https://blog.csdn.net/lihao21/article/details/71307115
- https://blog.csdn.net/lihao21/article/details/66097377
- https://blog.csdn.net/lihao21/article/details/64624796#commentBox
- https://bbs.csdn.net/topics/60361248
- https://blog.csdn.net/a3192048/article/details/84671340
- https://stackoverflow.com/questions/7976388/increasing-limit-of-fd-setsize-and-select