搭建 Elastic Stack 日志系统
Elastic Stack 是原 ELK Stack 在 5.0 版本加入 Beats 套件后的新称呼。Elastic Stack 在实时日志处理领域已开成开源界的第一选择。
本文讲述如何搭建 Elastic Stack 日志系统,使用的套件包括 Kibana,Elasticsearch,以及 Filebeat。搭建的环境选择阿里云 ECS 服务器,系统为 CentOS 7.4 64 位。
搭建 Kibana
Kibana 用来实现数据的可视化。Kibana 能够以图表的形式呈现数据,并且具有可扩展的用户界面,可以供我们全方位配置和管理 Elatic Stack。
搭建 Kibana 的步骤如下。
(1)添加 yum 源
在 /etc/yum.repos.d 目录创建 kibana.repo 文件,内容如下:
1 | [kibana-5.x] |
(2)安装 Kibana
运行安装命令:
yum install kibana
Kibana 安装后的主目录为 /usr/share/kibana,日志目录为 /var/log/kibana/ 。
(3)查看系统的初始化进程
查找进程 ID 为 1 的进程:
ps -p 1
输出:
1 | PID TTY TIME CMD |
可以看到我们的系统使用 systemd 作为初始化进程。
(4)配置 Kibana 随系统启动而启动
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable kibana.service
如果系统使用 init 初始化,则命令为
sudo chkconfig –add kibana
(5)修改 kibana 绑定的 IP
打开 kibana 的配置文件 /etc/kibana/kibana.yml,将 server.host 配置改成 “0.0.0.0”。
server.host: “0.0.0.0”
注意 ECS 实际上并没有公网IP的网卡,所以不能直接绑定公网IP,否则会导致 kibana 启动不成功。
(6)运行 Kibana
sudo systemctl start kibana.service
关闭 Kibana 命令为
sudo systemctl stop kibana.service
如果系统使用 init 实始化,则启动和关闭的命令为
sudo -i service kibana start
sudo -i service kibana stop
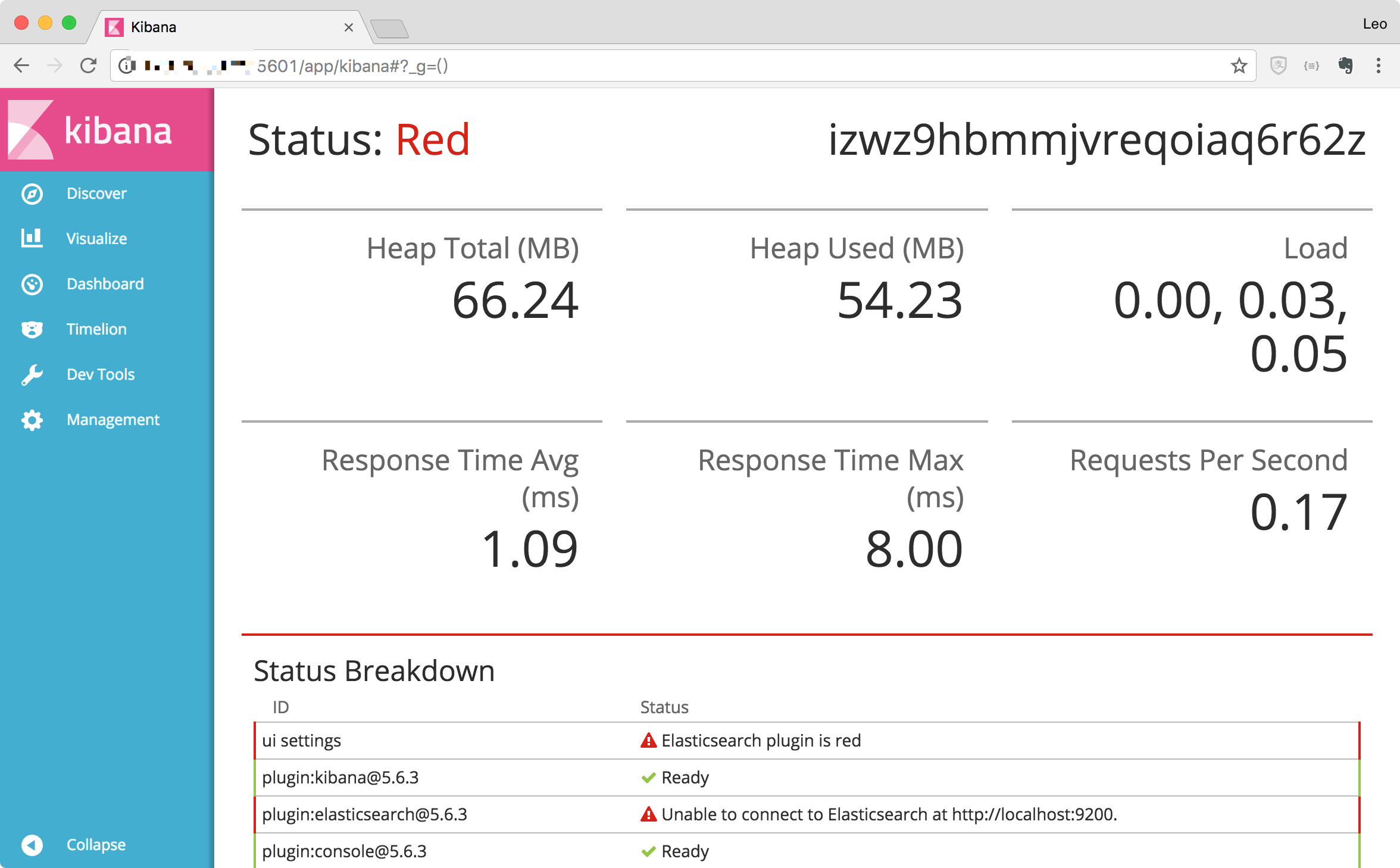
(7)验证运行成功
打开浏览器,输入 Kibana 安装所在机器的 ip:5601,便可以看到以下的页面,说明 Kibana 已成功安装 。
搭建 Elasticsearch
Elasticsearch 用来搜索、分析和存储数据。Elasticsearch 是基于 JSON 的分布式搜索和分析引擎,专为实现水平扩展,高可用和管理便捷而设计。
有了安装 Kibana 的经验,安装 Elasticsearch (下文称为 ES)就显得容易多了。
(1)安装 ES
yum install elasticsearch
安装后的日志目录为 /var/log/elasticsearch/,配置文件为 /etc/sysconfig/elasticsearch 和 /etc/elasticsearch/elasticsearch.yml。
(2)配置 ES 随系统启动而启动
如果使用 systemd 作为启动进程:
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable elasticsearch.service
如果使用 init 作为启动进程:
sudo chkconfig –add elasticsearch
(3)更改 ES 绑定的 IP 和端口
vim /etc/elasticsearch/elasticsearch.yml
写入 network.host: 0.0.0.0 配置。
如果需要更改端口,可以修改 http.port: 9200 配置。
(4)安装 Java 运行环境
ES 的运行依赖于 Java 运行环境,因此,需要安装 Java 运行环境。
yum install java-1.8.0-openjdk.x86_64
(5)启动 ES
如果使用 systemd 作为初始化进程,启动和关闭命令为
sudo systemctl start elasticsearch.service
sudo systemctl stop elasticsearch.service
如果需要查看 ES 的启动日志,可以使用命令:
journalctl –unit elasticsearch
这个命令对于查看 ES 启动是否成功很有帮助,如果启动失败,此命令也便于定位问题。
如果使用 init 作为初始化进程,启动和关闭命令
sudo -i service elasticsearch start
sudo -i service elasticsearch stop
(6)验证 ES 运行是否成功
浏览器输入 http://IP:9200/,可以看到以下输出:
{
“name”: “0rXIiW1”,
“cluster_name”: “elasticsearch”,
“cluster_uuid”: “zD4DE0jHR3yroGTQau0ENQ”,
“version”: {
“number”: “5.6.3”,
“build_hash”: “1a2f265”,
“build_date”: “2017-10-06T20:33:39.012Z”,
“build_snapshot”: false,
“lucene_version”: “6.6.1”
},
“tagline”: “You Know, for Search”
}
说明 ES 启动已成功。
搭建 Filebeat
Elastic Stack 提供 Beats 和 Logstash 套件来采集任何来源、任何格式的数据。Beats 是一个轻量级的采集器,支持从边缘机器向 Logstash 和 Elasticsearch 发送数据。Logstash 是一个动态数据收集管道,能够与 Elasticsearch 产生协同作用。
考虑到 Logstash 占用系统资源较多,我们采用 Filebeat 来作为我们的日志采集器。
(1)安装 Filebeat
yum install filebeat
Filebeat 的日志目录为 /var/log/filebeat,配置文件为 /etc/filebeat/filebeat.yml。
(2)修改 ES 的配置
在我们搭建的日志系统中,Filebeat 收集日志后发送给 ES ,故需要对 Filebeat 的 ES 配置进行修改。
打开 /etc/filebeat/filebeat.yml 文件,改更 ES 的配置为
1 | output.elasticsearch: |
使用 127.0.0.1 是由于 Filebeat 跟 ES 部署了在同一台机器,如果不在同一台机器,则需要根据实际情况填写 ES 的 IP。
(3)修改 Filebeat 监控的日志
打开 /etc/filebeat/filebeat.yml 文件,修改以下配置:
1 | - input_type: log |
即我们以目录 /root/logs 下的 *.log 日志作为 Filebeat 监控对象。
(4)运行 Filebeat
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable filebeat.service
sudo systemctl start filebeat.service
关闭命令为
sudo systemctl stop filebeat.service
如果以 init 作为初始化进程,则可以参考上述 Kibana 或者 ES 的命令,此处不再贅述。
(5)利用 Kibana 创建 index pattern
在 index pattern 输入框中输入 filebeat-*,即如下图所示:

(6)验证 Filebeat 运行是否正常
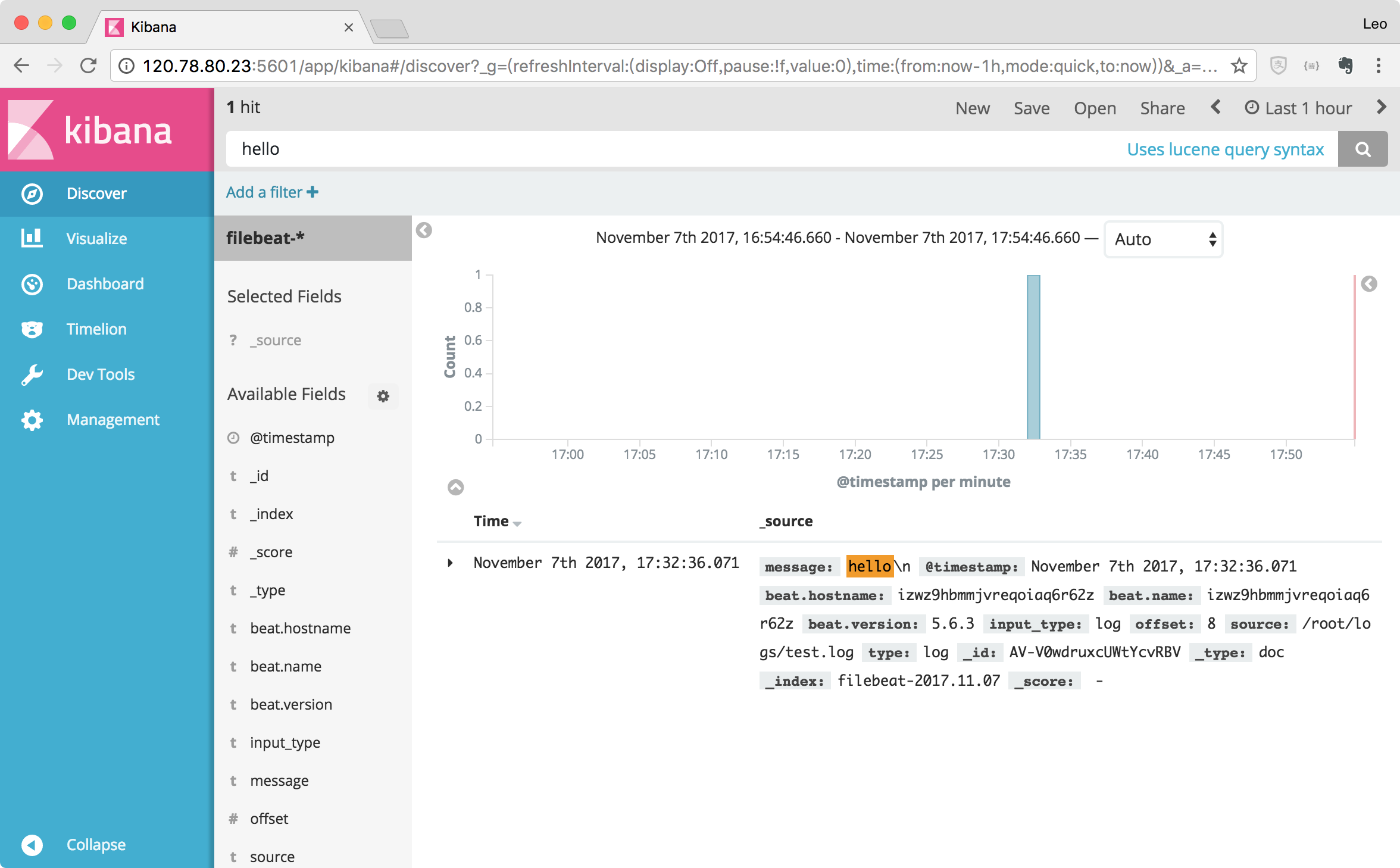
在 /root/logs 目录下创建 test.log 文件,然后执行
echo “hello\n” >> test.log
模拟日志文件产生了新的日志。
然后打开 Kibana,可以看到 hello 已显示出来。
(7)配置 Filebeat 支持多行日志
在日志文件中,常常会出现日志会占用多行的情况,例如 traceback 异常日志,输出 SQL 代码的日志,等。
假设我们的日志格式都是以 DEBUG, INFO, WARN, ERROR 开头,例如 DEBUG 日志如下
WARN|2017-10-27 13:42:19 000|pubservice.cpp(330)-
: LDAP认证失败,服务:FOS_101_0020,用户名: system
为了在 Kibana 中正常显示这种多行日志,可以通过修改 Filebeat 的配置来实现。
打开 /etc/filebeat/filebeat.yml 文件,修改以下配置:

其中 multiline.pattern 指定日志以 DEBUG, INFO, WARN, ERROR 开头。